El lenguaje HTML se adhiere al estándar WHATWG. Como es un lenguaje de marcado, un error en HTML no hace que la página web deje de funcionar, sino que el navegador la muestra lo mejor que puede.
Tener errores en HTML es problemático, ya que puede producir fallos inesperados y difíciles de reproducir, sobre todo cuando solo ocurren en un navegador. Así pues, es vital escribir un HTML válido.
Sin embargo, es muy fácil cometer errores y pasarlos por alto. Por eso es recomendable validar el código HTML; es decir, encontrar los fallos y corregirlos. Para eso existen los validadores, que, por lo general, simplemente muestran los errores. El más actualizado y recomendable es The Nu Html Checker. La W3C mantiene una instancia de ese validador que nos permite validar documentos HTML desde el navegador, ya sea introduciendo una URL, subiendo un archivo o introduciendo el código HTML en un formulario. Como este validador es libre, puedes instalarlo en tu ordenador fácilmente.
El validador en línea funciona bien si solo tienes que validar unas
pocas páginas web de vez en cuando, pero no sirve para validar un sitio
web entero. Para ello recomiendo usar la versión de The Nu Html
Checker que se ejecuta en terminal. Esta se encuentra en el archivo
vnu.jar (hace falta tener Java instalado).
En mi caso, yo utilizo el paquete html5validator, ya que trabajo principalmente con Python y no supone una dependencia adicional. Para instalar este paquete en una distribución de GNU/Linux basada en Debian solo hay que ejecutar...
sudo apt install default-jre
sudo pip3 install html5validator
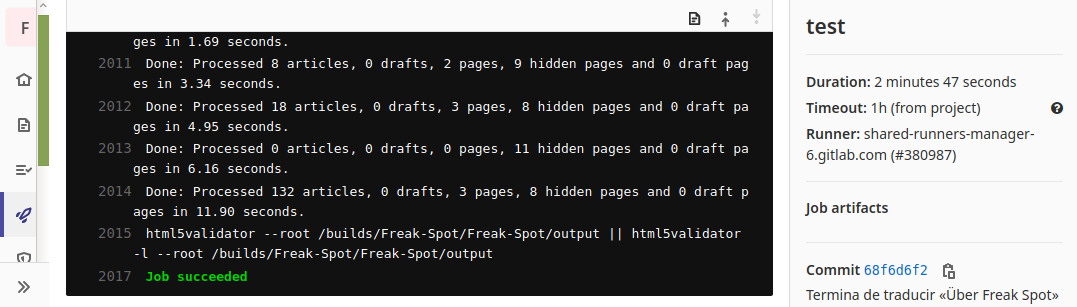
Al terminar la instalación tenemos un programa llamado html5validator que podemos ejecutar desde la terminal:
html5validator index.html
Un argumento súper útil es --root, que permite validar todos los
archivos de un directorio, y del directorio dentro del directorio...,
así hasta que haya validado todo. Yo lo uso especificando el directorio
raíz de mi sitio web, validando así el sitio web completo en unos
segundos.
html5validator --root sitio-web/
Lo ideal es usar algún tipo de integración continua para no tener que ejecutar manualmente la anterior instrucción cada vez que cambias algo en la página web. Para ello yo uso GitLab CI. De este modo, mantengo este sitio web y muchos otros sin errores de HTML, y cuando rompo algo, me entero pronto.