Muitos jornais têm acesso pago que nos impede de ver o conteúdo
completo dos artigos. Existem, no entanto, alguns truques para os evitar.
Uma extensão útil do navegador que nos permite contornar esses muros de
pagamento é Bypass Paywalls
Clean.
Esta extensão funciona para sítios web populares, e outros podem ser
facilmente adicionados. Como funciona? Basicamente, a extensão utiliza
truques tais como desactivar o JavaScript, desactivar os cookies ou alterar
o agente do utilizador para o de um rastreador web
conhecido (como o Googlebot).
Não há necessidade de instalar a extensão anterior se não queres.
Continua a ler para descobrir em detalhe os truques que podes utilizar
para evitar a maior parte dos muros de pagamento.
A luz azul é emitida por fontes naturais, tais como o sol e ecrãs de dispositivos electrónicos. Aproximadamente um terço de toda a luz visível para os seres humanos é considerada azul. A exposição excessiva à luz azul causa graves problemas de saúde.
Muitas pessoas dão uma explicação pessoal sobre o porquê de protegerem
ou não a sua privacidade. Aqueles que não se importam muito são ouvidos
dizer que não têm nada a esconder. Aqueles que o fazem para se
protegerem de empresas sem escrúpulos, estados repressivos, e assim por
diante. Em ambas as posições é muitas vezes erradamente assumido que a
privacidade é um assunto pessoal, e não é.
A privacidade é tanto um assunto individual como um assunto público. Os
dados recolhidos por grandes empresas e governos são raramente
utilizados numa base individual. Podemos compreender a privacidade como
um direito do indivíduo em relação à comunidade, como diz
Edward Snowden:
Argumentar que não te preocupas com a privacidade porque não tens
nada a esconder não é diferente de dizer que não te preocupas com a
liberdade de expressão porque não tens nada a dizer.
Os teus dados podem ser utilizados para o bem ou para o mal. Os dados
recolhidos desnecessariamente e sem autorização são muitas vezes
utilizados para fins indevidos.
Estados e grandes empresas tecnológicas violam flagrantemente a nossa
privacidade. Muitas pessoas concordam tacitamente argumentando que nada
pode ser feito para o mudar: as empresas têm demasiado poder e os
governos não farão nada para mudar as coisas. E, certamente, essas pessoas
estão habituadas a dar poder às empresas que ganham dinheiro com os seus
dados e assim dizem aos Estados que não vão ser uma pedra no seu sapato
quando quiserem implementar políticas de vigilância de massa. No final,
prejudicam a privacidade daqueles que se preocupam.
A acção colectiva começa com o indivíduo. Cada pessoa deve refletir
sobre se está a fornecer dados sobre si própria que não deve, se está a
encorajar o crescimento de empresas antiprivacidade e, mais importante
ainda, se está a comprometer a privacidade dos que lhe são próximos. A
melhor maneira de proteger a informação privada é não a divulgar. Com a
consciência do problema, os projectos em prol da privacidade podem ser
apoiados.
Os dados pessoais são muito valiosos — tanto que alguns chamam-nos o
«novo petróleo» — não só porque podem ser vendidos a terceiros,
mas também porque dão poder a quem quer que os tenha. Quando os damos
aos governos, damos-lhes o poder de nos controlarem. Quando os damos às
empresas, estamos a dar-lhes poder para influenciarem o nosso
comportamento. Em última análise, a privacidade é importante porque nos
ajuda a preservar o poder que temos sobre as nossas vidas, que eles
estão tão empenhados em tirar. Eu não vou dar ou vender os meus dados,
e tu?
O HTML adere à norma
WHATWG. Como é uma linguagem de
marcação, um erro em HTML não faz com que a página web deixe de
funcionar, mas o navegador apresenta-a o melhor que pode.
Ter erros em HTML é problemático, pois pode produzir falhas inesperadas e
difíceis de reproduzir, especialmente quando estas ocorrem apenas num
navegador. É portanto vital escrever HTML válido.
No entanto, é muito fácil cometer erros e ignorá-los. É por isso que é
aconselhável validar o código HTML, ou seja, encontrar os erros e
corrigi-los. Para este fim, existem validadores, que normalmente
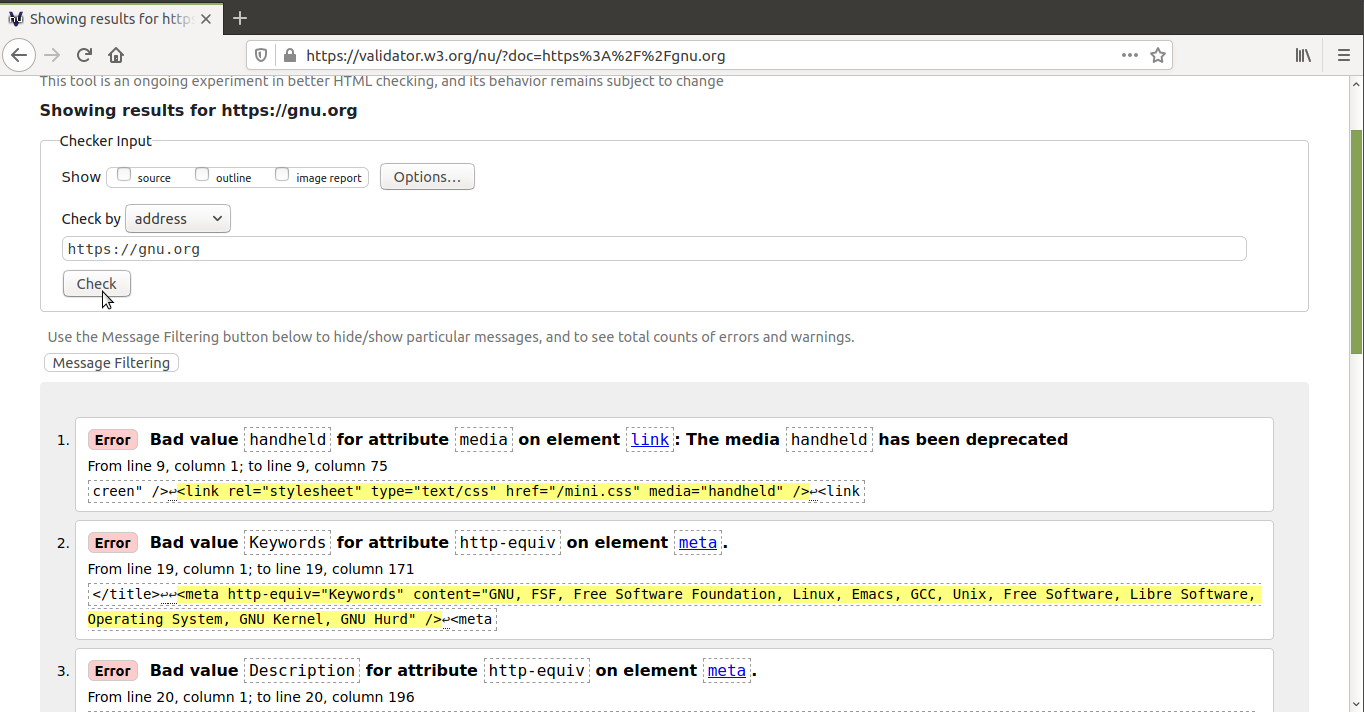
simplesmente exibem os erros. O mais actualizado e recomendado é The Nu
Html Checker. O W3C mantém uma
instância deste validador que nos permite validar documentos HTML a
partir do navegador, quer introduzindo um
URL, carregando um
ficheiro ou introduzindo o código
HTML num formulário. Como este
validador é livre, podes instalá-lo facilmente no teu computador.
O validador em linha funciona bem se precisar de validar apenas algumas
páginas web de vez em quando, mas não é adequado para validar um sítio
web inteiro. Para isso recomendo a utilização da versão terminal do Nu
Html Checker. Isto pode ser encontrado no ficheiro vnu.jar (Java deve
ser instalado).
No meu caso, utilizo o pacote html5validator, uma vez que trabalho
principalmente com Python e não requer qualquer dependência adicional.
Para instalar este pacote numa distribuição GNU/Linux baseada em Debian,
só precisas de correr...
Quando a instalação estiver concluída, temos um programa chamado
html5validator que podemos executar a partir do terminal:
html5validatorindex.html
Um argumento super útil é --root, que nos permite validar todos os
ficheiros de um directório, e o directório dentro do directório..., até
ter validado tudo. Utilizo-o especificando o directório raiz do meu
sítio web, validando todo o sítio web em poucos segundos.
html5validator--rootsítio-web/
Idealmente, deverás utilizar algum tipo de integração
contínua
para que não tenhas de executar manualmente o comando acima sempre que
mudar alguma coisa na página web. Eu utilizo o GitLab
CI para isto. Desta
forma, mantenho este sítio web e muitos outros livres de erros HTML, e
quando quebro algo, o descubro cedo.
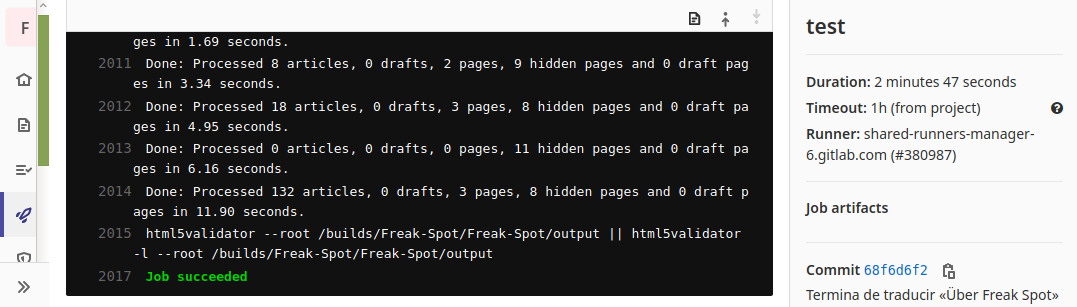
Este teste GitLab CI mostra que
o website foi gerado com sucesso e sem erros HTML.