O HTML adere à norma WHATWG. Como é uma linguagem de marcação, um erro em HTML não faz com que a página web deixe de funcionar, mas o navegador apresenta-a o melhor que pode.
Ter erros em HTML é problemático, pois pode produzir falhas inesperadas e difíceis de reproduzir, especialmente quando estas ocorrem apenas num navegador. É portanto vital escrever HTML válido.
No entanto, é muito fácil cometer erros e ignorá-los. É por isso que é aconselhável validar o código HTML, ou seja, encontrar os erros e corrigi-los. Para este fim, existem validadores, que normalmente simplesmente exibem os erros. O mais actualizado e recomendado é The Nu Html Checker. O W3C mantém uma instância deste validador que nos permite validar documentos HTML a partir do navegador, quer introduzindo um URL, carregando um ficheiro ou introduzindo o código HTML num formulário. Como este validador é livre, podes instalá-lo facilmente no teu computador.
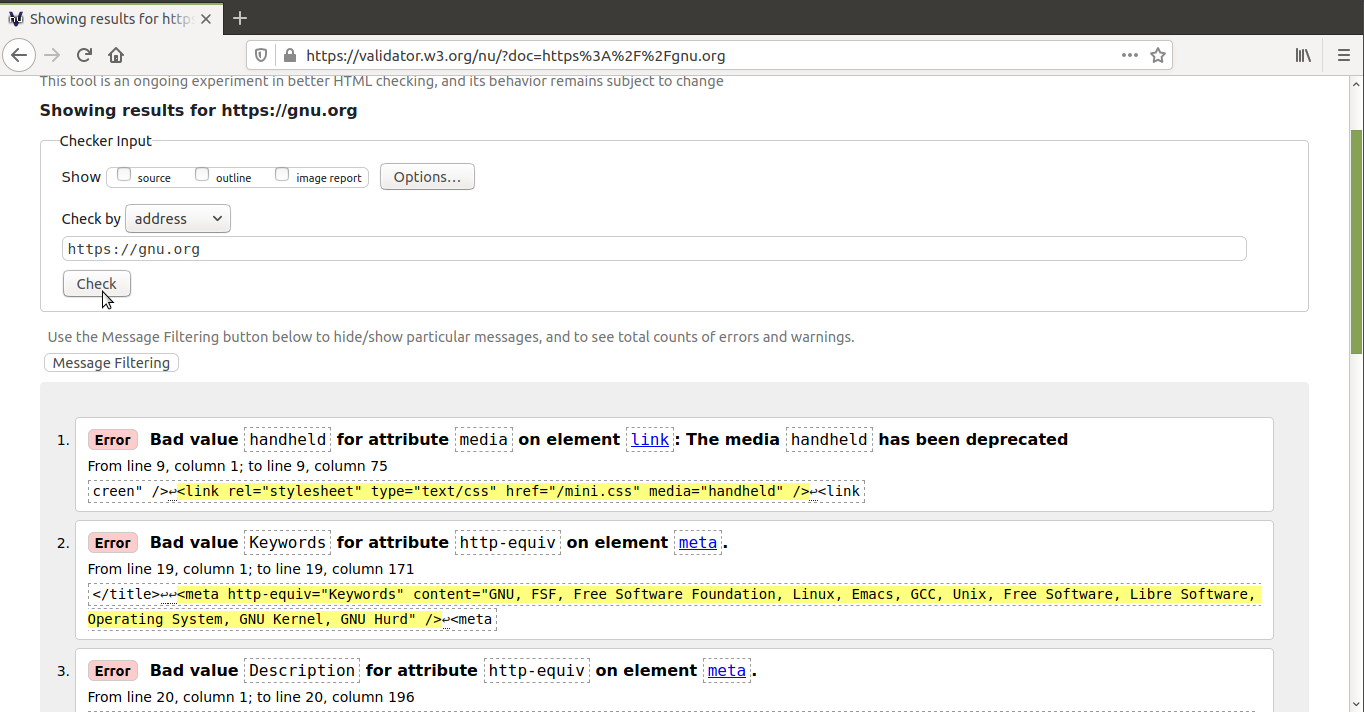
O validador em linha funciona bem se precisar de validar apenas algumas
páginas web de vez em quando, mas não é adequado para validar um sítio
web inteiro. Para isso recomendo a utilização da versão terminal do Nu
Html Checker. Isto pode ser encontrado no ficheiro vnu.jar (Java deve
ser instalado).
No meu caso, utilizo o pacote html5validator, uma vez que trabalho principalmente com Python e não requer qualquer dependência adicional. Para instalar este pacote numa distribuição GNU/Linux baseada em Debian, só precisas de correr...
sudo apt install default-jre
sudo pip3 install html5validator
Quando a instalação estiver concluída, temos um programa chamado html5validator que podemos executar a partir do terminal:
html5validator index.html
Um argumento super útil é --root, que nos permite validar todos os
ficheiros de um directório, e o directório dentro do directório..., até
ter validado tudo. Utilizo-o especificando o directório raiz do meu
sítio web, validando todo o sítio web em poucos segundos.
html5validator --root sítio-web/
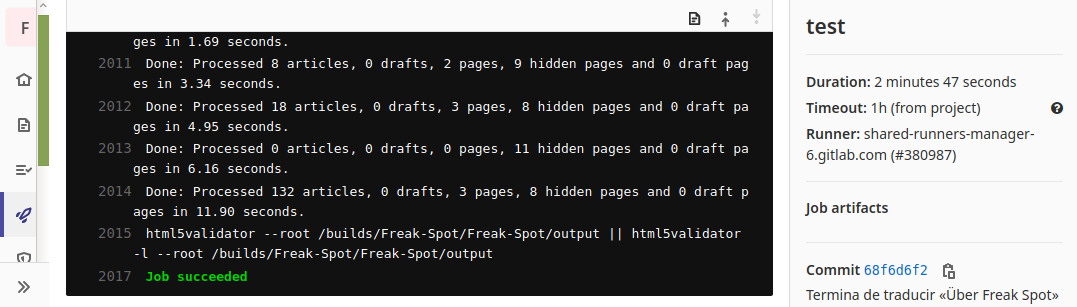
Idealmente, deverás utilizar algum tipo de integração contínua para que não tenhas de executar manualmente o comando acima sempre que mudar alguma coisa na página web. Eu utilizo o GitLab CI para isto. Desta forma, mantenho este sítio web e muitos outros livres de erros HTML, e quando quebro algo, o descubro cedo.