Eble vi trovis URL-jn, kiuj finiĝas per suprenstreko (kiel
https://freakspot.net/eo/ aŭ /,
servila dosieruja radiko), kaj aliajn, kiuj ne finiĝas per suprenstreko
(kiel ĉi tiu : https://www.gnu.org/gnu/gnu.html). Kio estas la
diferenco? Ĉu gravas?
URL estas esence adreso al
afero. La URL-j ne nur aludas retejojn, sed ankaŭ aliajn specojn de
aferoj. Kelkaj ekzemploj de URL-skemoj estas http, https, ftp,
telnet, data kaj mailto. En ĉi tiu artikolo mi parolas pri
retejoj, kiuj uzas la http- aŭ la https-skemon.
URL-adresoj, kiuj finiĝas per suprenstreko, referencas dosierujon;
tiuj, kiuj ne, referencas dosieron. Kiam vi klakas la ligilon
https://freakspot.net/eo, la servilo rimarkas, ke la bezonata adreso
ne estas dosiero, kaj iras al https://freakspot.net/eo/. Ĉi tie ĝi
trovas ĉefan dosieron nomitan index.html aŭ index kun alia finaĵo
kaj montras ĝian enhavon.
Kelkfoje utilas prezenti datumojn per arba strukturo kiel tiu, kiun
kreas la tree-programo. La tree-programo kreas eligon de arbo de
dosierujoj kiel tiu ĉi:
Por prezenti la komandon tiel, kiel ĝi aperas en terminalo, mi uzis la
HTML-etikedojn <samp> kaj <pre> (<pre><samp>eliro de
tree</samp></pre>). Sed kio okazas, se mi volas inkludi ligilon aŭ uzi
aliajn HTML-elementojn, aŭ CSS? Tiuokaze ni devas uzi CSS por montri la
branĉan aspekton.
La lingvo HTML konformas
kun la WHATWG-normo. Ĉar ĝi estas
markolingvo, eraro en HTML
ne kaŭzas, ke la paĝaro ceŝu funkcii, sed la retumilo ĝin montras kiel
eble plej bone.
Havi erarojn en HTML estas problema, ĉar ĝi povas aperigi neatenditajn
kaj malfacile reprodukteblajn erarojn, ĉefe kiam ili nur aperas en
konkreta retumilo. Do estas necesega skribi validan HTML-n.
Tamen estas facile fari erarojn kaj ĝin pretervidi. Sekve oni rekomendas
validigi la HTML-kodon, tio estas, trovi la erarojn kaj korekti ilin.
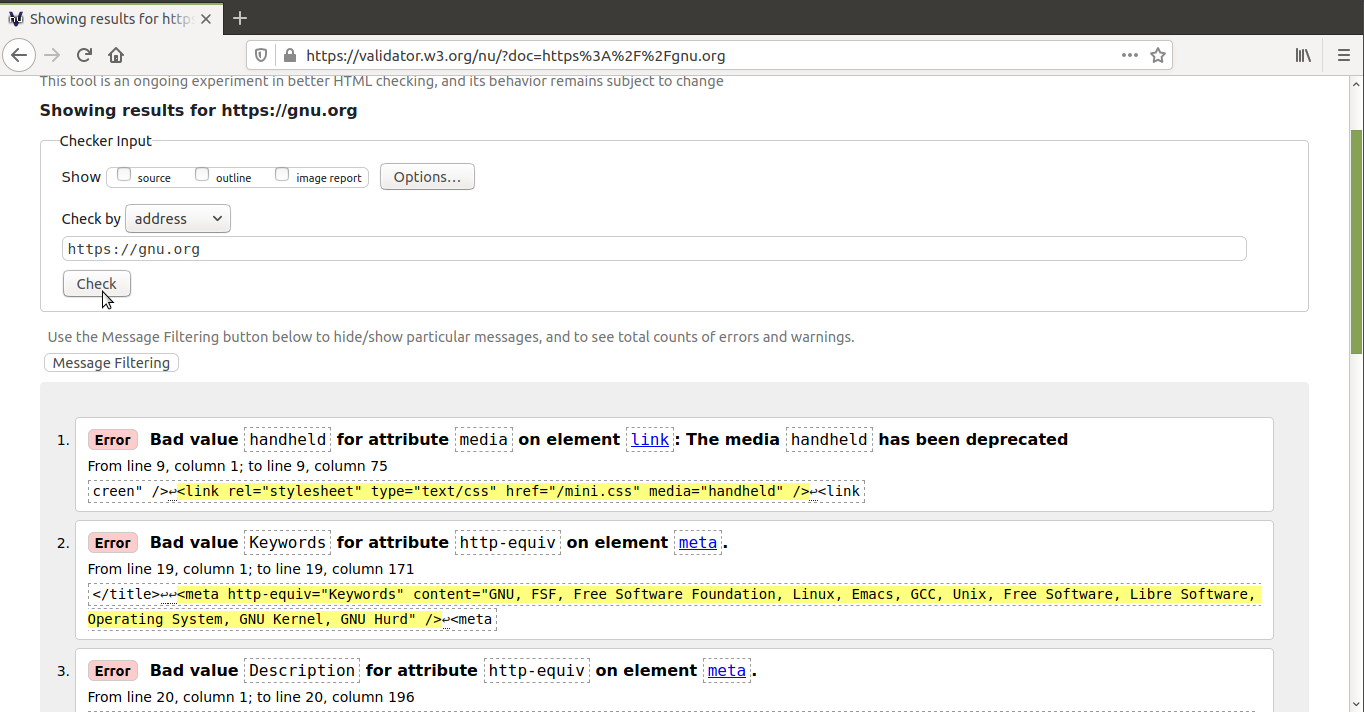
Por tio ekzistas validiloj, kiuj generale simple montras erarojn. La
plej ĝisdatigita kaj rekomendinda estas The Nu Html
Checker. La W3C subtenas nodon
de ĉi tiu validilo, kiu permesas al ni validigi HTML-dokumentojn en la
retumilo, enigante URL-n, alŝutante
dosieron kaj skribante la kodon en
formularo. Ĉar ĉi tiu validilo
estas libera programaro, vi povas instali ĝin facile en via komputilo.
La reta validilo bone funkcias, se vi nur devas validigi kelkajn
retejojn okaze, sed ĝi ne utilas por validigi tutan retejon. Por tio mi
rekomendas uzi la version de The Nu Html Checker, kiun oni plenumas en
terminalo. Ĝi troviĝas en la dosiero vnu.jar (Java estas bezona).
Mi persone uzas la
html5validator-pakon, ĉar mi
laboras kun Python kaj ĝi ne signifas kroma dependaĵo. Por instali ĉi
tiun pakon en GNU/Linukso-distribuo bazita sur Debiano oni nur devas
plenumi...
Post la instalo havas ni programon kun la nomo html5validator, kiun ni
povas plenumi en la terminalo:
html5validatorindex.html
Utilega argumento estas --root, kiu permesas validigi ĉiujn dosierojn
en dosierujo, kaj en la dosierujo ene de la dosierujo..., tiel ĝis ĉiun
ĝi validigis. Mi uzas ĝin donante la kernan dosierujon de mia retejo,
validante tiel la tutan retejon en kelkaj sekundoj.
html5validator--rootretejo/
Estas inde uzi ian kontinuan
integriĝon por
eviti plenumi mane la antaŭan komandon ĉiam, kiam vi ŝanĝas ion en la
retejo. Por tio mi uzas GitLab
CI. Tiel mi prizorgas
ĉi tiun retejon kaj multajn aliajn sen HTML-eraroj kaj kiam mi rompas
ion, mi rimarkas baldaŭ.
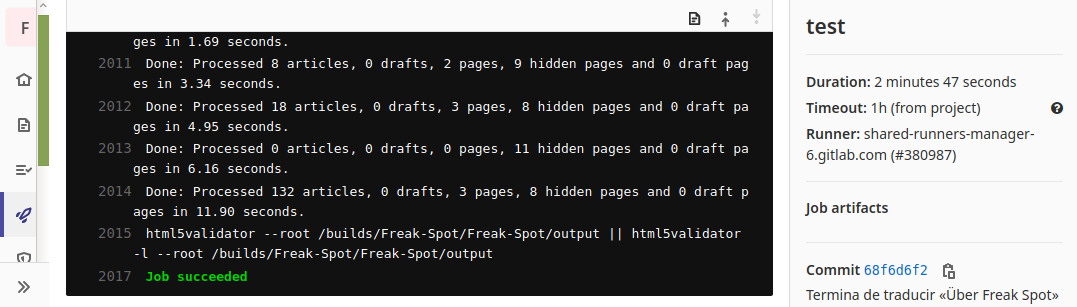
Ĉi tiu testo de GitLab CI
montras, ke la retejo estis kreita sukcese kaj sen HTML-eraroj.