
Un CAPTCHA es una prueba que se realiza para diferenciar ordenadores de humanos. Se usa principalmente para evitar mensajes basura (en inglés llamados spam).
Un programa que realiza esta prueba es reCAPTCHA, que fue publicado el 27 de mayo de 2007 y adquirido por Google en septiembre de 20091. Dicho programa es utilizado en páginas web de todo el mundo.
reCAPTCHA se ha utilizado mucho para digitalizar textos gracias al trabajo gratuito de millones de usuarios, quienes son capaces de identificar palabras incomprensibles por los ordenadores. La gran mayoría no sabe que Google se está aprovechando de su trabajo; a otras personas no les importa.
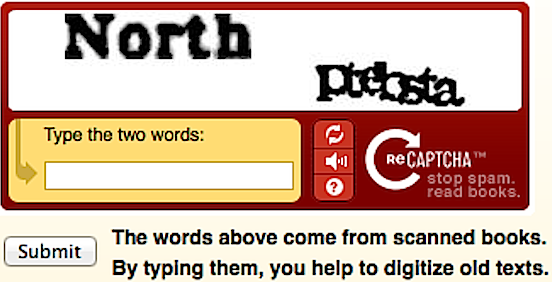
En el artículo «Deciphering Old Texts, One Woozy, Curvy Word at a Time» publicado en el periódico The New York Times se informaba de que los usuarios de Internet habían terminado de digitalizar usando reCAPTCHA el archivo de dicho periódico, publicado desde 1851. Según decía el creador de reCAPTCHA entonces, los usuarios, o mejor dicho «usados», descifraban alrededor de 200 millones de CAPTCHAs por día, tardando 10 segundos en resolver cada uno. Ese trabajo equivale a 500 000 horas de trabajo al día2.
Un CAPTCHA no solo se puede usar con texto difícil de entender, sino también con imágenes. Por ejemplo, Google también hace uso de reCAPTCHA para identificar imágenes de establecimientos, señales de tráfico, etc., realizadas para Google Maps. Asimismo, los reCAPTCHAS de Google se utilizan para otros propósitos que no conocen los usados.

Solo Google sabe el beneficio económico que le reporta este sistema de explotación. Es imposible auditar reCAPTCHA porque es software privativo, y los usados no tienen ningún poder. Lo único que pueden hacer es negarse a resolver CAPTCHAs como los de Google para dejar de ser usados.
Ahora Google utiliza un método de identificación que les ahorra tiempo a los usados y evita que tengan que descifrar textos e imágenes. Los usados ahora solo deben pulsar un botón. Este mecanismo impone la ejecución de código JavaScript desconocido por los usados, el cual supone un gran peligro para la privacidad. Google puede obtener muchísima información de los usados que usen este mecanismo, que probablemente luego venda por cuantiosas sumas.
Además, reCAPTCHA discrimina a los usuarios discapacitados y los usuarios de Tor: por un lado, los desafíos presentados a usuarios discapacitados son más largos y difíciles de resolver; por otro lado, quienes navegan de forma privada por Internet tienen que resolver un desafío más difícil y que requiere más tiempo.
El artículo escrito por el creador de reCAPTCHA3 cuando este fue adquirido por Google decía:
Mejorar la disponibilidad y accesibilidad de toda la información en Internet es realmente importante para nosotros, así que estamos deseando mejorar esta tecnología con el equipo de reCAPTCHA.
Sin embargo, el trabajo realizado usando reCAPTCHA no se encuentra disponible ni accesible en muchos casos. Los datos son presentados de forma que beneficia económicamente a Google y a otras empresas. Los usados que ayudaron a digitalizar el archivo de The New York Times tienen que pagar viendo anuncios cuando consultan el archivo que ellos mismos ayudaron a digitalizar sin obtener nada a cambio.
-
Deciphering Old Texts, One Woozy, Curvy Word at a Time (28 de marzo de 2011). The New York Times. Consultado el 5 de mayo de 2017. ↩
-
Teaching computers to read: Google acquires reCAPTCHA (16 de septiembre de 2009). Official Google Blog. Consultado el 5 de mayo de 2017. ↩
Comentarios